
-
- Downloads
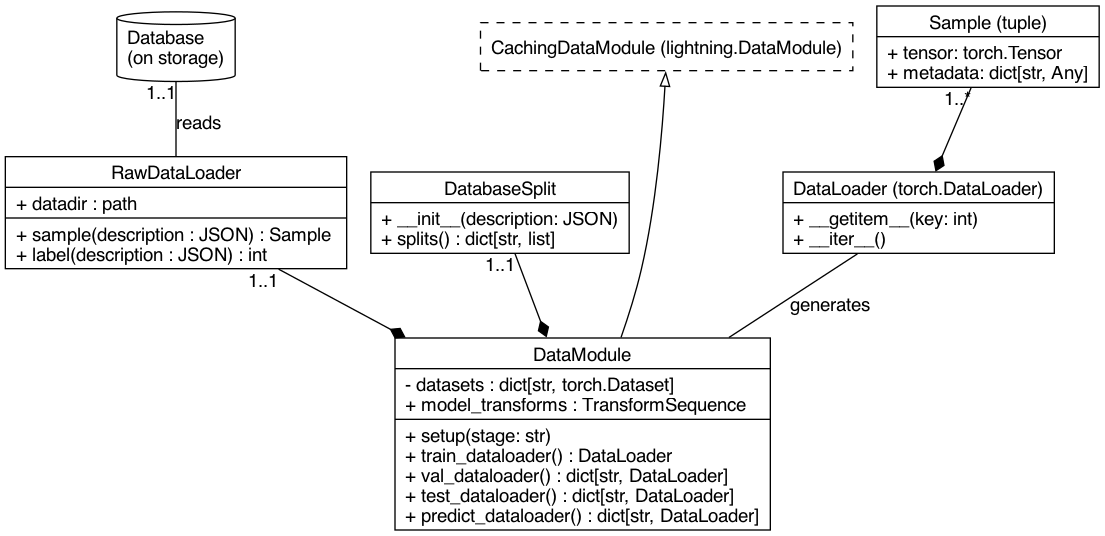
[doc] Add data-model diagram (closes #24)
Showing
- .reuse/dep5 1 addition, 0 deletions.reuse/dep5
- doc/data-model.rst 98 additions, 0 deletionsdoc/data-model.rst
- doc/data_model.rst 0 additions, 69 deletionsdoc/data_model.rst
- doc/img/data-model.dot 89 additions, 0 deletionsdoc/img/data-model.dot
- doc/img/data-model.png 0 additions, 0 deletionsdoc/img/data-model.png
- doc/index.rst 1 addition, 1 deletiondoc/index.rst
doc/data-model.rst
0 → 100644
doc/data_model.rst
deleted
100644 → 0
doc/img/data-model.dot
0 → 100644
doc/img/data-model.png
0 → 100644
{kind=link}
87.5 KiB