Skip to content
GitLab
Explore
Sign in
Primary navigation
Search or go to…
Project
mednet
Manage
Activity
Members
Labels
Plan
Issues
Issue boards
Milestones
Code
Merge requests
Repository
Branches
Commits
Tags
Repository graph
Compare revisions
Build
Pipelines
Jobs
Pipeline schedules
Artifacts
Deploy
Releases
Package Registry
Model registry
Operate
Environments
Terraform modules
Monitor
Incidents
Analyze
Value stream analytics
Contributor analytics
CI/CD analytics
Repository analytics
Model experiments
Help
Help
Support
GitLab documentation
Compare GitLab plans
Community forum
Contribute to GitLab
Provide feedback
Keyboard shortcuts
?
Snippets
Groups
Projects
Show more breadcrumbs
medai
software
mednet
Commits
34a0feff
Commit
34a0feff
authored
6 months ago
by
André Anjos
Browse files
Options
Downloads
Patches
Plain Diff
[doc] Improve data-model description
parent
05e4c021
No related branches found
Branches containing commit
No related tags found
Tags containing commit
No related merge requests found
Pipeline
#91257
passed
6 months ago
Stage: qa
Stage: doc
Stage: dist
Stage: test
Changes
4
Pipelines
1
Hide whitespace changes
Inline
Side-by-side
Showing
4 changed files
doc/data-model.rst
+49
-30
49 additions, 30 deletions
doc/data-model.rst
doc/img/data-model-dark.png
+0
-0
0 additions, 0 deletions
doc/img/data-model-dark.png
doc/img/data-model-lite.png
+0
-0
0 additions, 0 deletions
doc/img/data-model-lite.png
doc/img/data-model.dot
+1
-1
1 addition, 1 deletion
doc/img/data-model.dot
with
50 additions
and
31 deletions
doc/data-model.rst
+
49
−
30
View file @
34a0feff
...
...
@@ -38,18 +38,27 @@ user A may be under ``/home/user-a/databases/database-1`` and
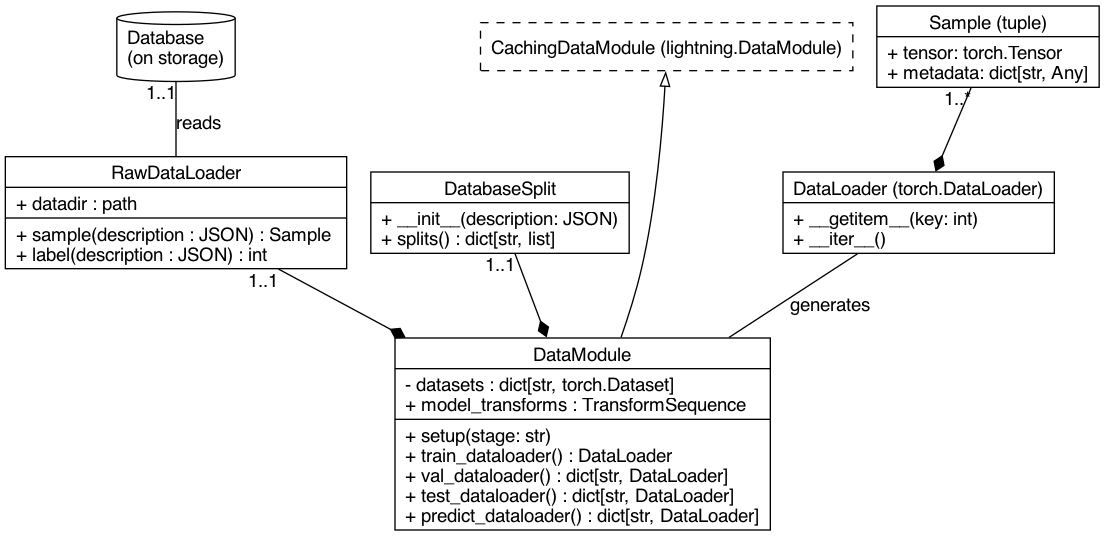
Sample
------
The in-memory representation of the raw database samples. In this package, it
is specified as a two-tuple with a tensor (or a dictionary with multiple
tensors), and metadata (typically label, name, etc.).
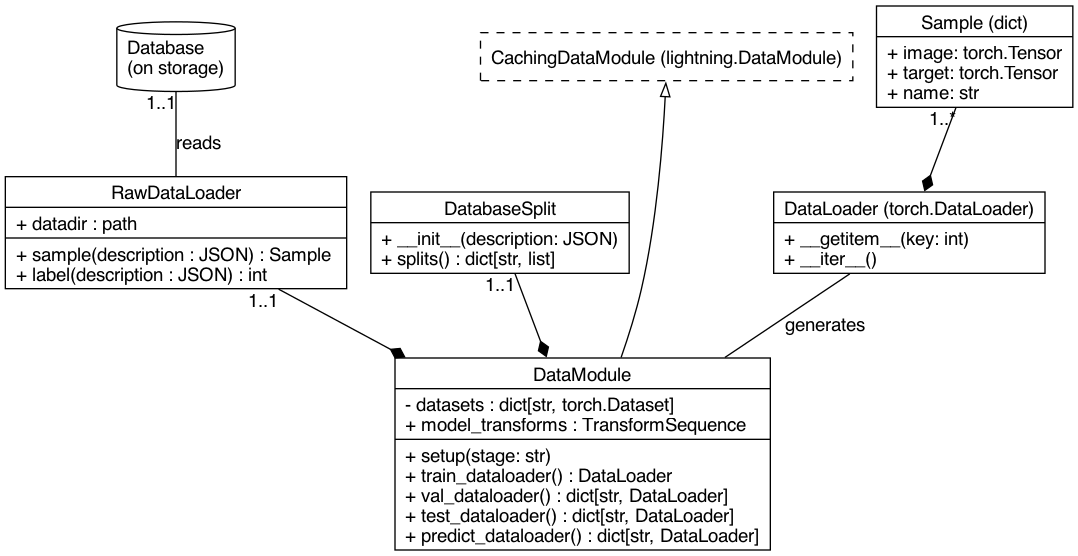
The in-memory representation of the raw database ``Sample``. It is specified
as a dictionary containing at least the following keys:
* ``image`` (:py:class:`torch.Tensor`): the image to be analysed
* ``target`` (:py:class:`torch.Tensor`): the target for the current task
* ``name`` (:py:class:`str`): a unique name for this sample
Optionally, depending on the task, the following keys may also be present:
* ``mask`` (:py:class:`torch.Tensor`): an inclusion mask for the input image
and targets. If set, then it is used to evaluate errors only within the
masked area.
RawDataLoader
-------------
A c
oncrete "functor"
that allows one to load the raw data and associated
metadata,
to create a in-memory Sample representation. RawDataLoader
s are
typically
D
atabase-specific due to raw data and metadata encoding varying
quite
a lot on different databases. RawDataLoaders may also embed various
A c
allable object
that allows one to load the raw data and associated
metadata,
to create a in-memory
``
Sample
``
representation.
Concrete ``
RawDataLoader
``\s
are
typically
d
atabase-specific due to raw data and metadata encoding varying
quite
a lot on different databases.
``
RawDataLoader
``\
s may also embed various
pre-processing transformations to render data readily usable such as
pre-cropping of black pixel areas, or 16-bit to 8-bit auto-level conversion.
...
...
@@ -57,27 +66,35 @@ pre-cropping of black pixel areas, or 16-bit to 8-bit auto-level conversion.
TransformSequence
-----------------
A sequence of callables that allows one to transform torch.Tensor objects into
other torch.Tensor objects, typically to crop, resize, convert Color-spaces,
and the such on raw-data.
A sequence of callables that allows one to transform :py:class:`torch.Tensor`
objects into other :py:class:`torch.Tensor` objects, typically to crop, resize,
convert color-spaces, and the such on raw-data. TransformSequences are used in
two main parts of this library: to power raw-data loading and transformations
required to fit data into a model (e.g. ensuring images are grayscale or
resized to a certain size), and to implement data-augmentations for
training-time usage.
DatabaseSplit
-------------
A dictionary that represents an organization of the available raw data in the
database to perform an evaluation protocol (e.g. train, validation, test)
through datasets (or subsets). It is represented as dictionary mapping dataset
names to lists of "raw-data" sample representations, which vary in format
depending on Database metadata availability. RawDataLoaders receive this raw
representations and can convert these to in-memory Sample's.
A dictionary-like object that represents an organization of the available raw
data in the database to perform an evaluation protocol (e.g. train, validation,
test) through datasets (or subsets). It is represented as dictionary mapping
dataset names to lists of "raw-data" ``Sample`` representations, which vary in
format depending on Database metadata availability. ``RawDataLoaders`` receive
this raw representations and can convert these to in-memory ``Sample``\s. The
:py:class:`mednet.data.split.JSONDatabaseSplit` is concrete example of a
``DatabaseSplit`` implementation that can read the split definition from JSON
files, and is thoroughly at the library to represent the various database
splits supported.
ConcatDatabaseSplit
-------------------
An extension of a DatabaseSplit, in which the split can be formed by
cannibali
sing various other DatabaseSplits to construct a new evaluation
An extension of a
``
DatabaseSplit
``
, in which the split can be formed by
reu
sing various other
``
DatabaseSplit
``\
s to construct a new evaluation
protocol. Examples of this are cross-database tests, or the construction of
multi-Database training and validation subsets.
...
...
@@ -85,20 +102,22 @@ multi-Database training and validation subsets.
Dataset
-------
An iterable object over in-memory Samples, inherited from the pytorch Dataset
definition. A dataset in our framework may be completely cached in memory or
have in-memory representation of samples loaded on demand. After data loading,
our datasets can optionally apply a TransformSequence, composed of
pre-processing steps defined on a per-model level before optionally caching
in-memory Sample representations. The "raw" representation of a dataset are the
split dictionary values (ie. not the keys).
An iterable object over in-memory ``Sample``\s, inherited from the
:py:class:`.torch.utils.data.Dataset`. A ``Dataset`` in this framework may be
completely cached in memory, or have in-memory representation of ``Sample``\s
loaded on demand. After data loading, ``Dataset``\s can optionally apply a
``TransformSequence``, composed of pre-processing steps defined on a per-model
level before optionally caching in-memory ``Sample`` representations. The "raw"
representation of a ``Dataset`` are the split dictionary values (ie. not the
keys).
DataModule
----------
A DataModule aggregates Splits and RawDataLoaders to provide lightning a
known-interface to the complete evaluation protocol (train, validation,
prediction and testing) required for a full experiment to take place. It
automates control over data loading parallelisation and caching inside our
framework, providing final access to readily-usable pytorch DataLoaders.
A ``DataModule`` aggregates ``DatabaseSplit``\s and ``RawDataLoader``\s to
provide lightning a known-interface to the complete evaluation protocol (train,
validation, prediction and testing) required for a full experiment to take
place. It automates control over data loading parallelisation and caching
inside the framework, providing final access to readily-usable pytorch
``DataLoader``\s.
This diff is collapsed.
Click to expand it.
doc/img/data-model-dark.png
+
0
−
0
View replaced file @
05e4c021
View file @
34a0feff
86.4 KiB
|
W:
|
H:
75.2 KiB
|
W:
|
H:
2-up
Swipe
Onion skin
This diff is collapsed.
Click to expand it.
doc/img/data-model-lite.png
+
0
−
0
View replaced file @
05e4c021
View file @
34a0feff
87.5 KiB
|
W:
|
H:
78.2 KiB
|
W:
|
H:
2-up
Swipe
Onion skin
This diff is collapsed.
Click to expand it.
doc/img/data-model.dot
+
1
−
1
View file @
34a0feff
...
...
@@ -39,7 +39,7 @@ digraph G {
]
Sample
[
label
=
"{Sample (
tuple)|+ tensor: torch.Tensor\l+ metadata: dict[str, Any]
\l}"
label
=
"{Sample (
dict)|+ image: torch.Tensor\l+ target: torch.Tensor\l+ name: str
\l}"
]
DataLoader
[
...
...
This diff is collapsed.
Click to expand it.
Preview
0%
Loading
Try again
or
attach a new file
.
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Save comment
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}
{kind=link}
{kind=link}